In my previous post I have demonstrated the
installation of multi-node Cloudera cluster. Here I will demonstrate how to kerberize a Cloudera cluster.
Introduction to Kerberos
Kerberos is a network authentication protocol that allows both users and machines to identify themselves on a network, defining and limiting access to services that are configured by the administrator. Kerberos uses secret-key cryptography strong authentication by providing user-to-server authentication. It was built on an assumption that network connections are unreliable.
Terminology
Below are a few common terms used in Kerberos:
Principal
A user/service in Kerberos is called Principal.
A principal is made up of three distinct components:
- Primary (User component): The first component of principal is called the Primary. It is an arbitrary string and may be an operating system username of a user or the name of a service.
- Instance: Principal's first component "primary" is followed by and optional section called "instance". An instance is separated from the primary by a slash. An instance is used to create principals that are used by users in special roles or to define the host on which a service runs. Instance name is the FQDN of the host that runs that service.
- Realm: A realm is similar to a domain in DNS that establishes an authentication administrative domain. In other words, Kerberos realm defines a group of principals. A realm, by convention, are always written in uppercase characters.
A username can be an existing Unix account that is used by Hadoop daemons, such as hdfs or mapred or user's UNIX account. Hadoop does not support more than two-component principal names. Each service and sub-service in hadoop must have it's own principal. A principal name in given realm consists of a primary name and an instance name. In our case a principal can be in the following format, username/fully-qualified-domain-name@CDH.DEMO.
Tickets
The authentication server issues the tickets to the clients so that the client can present the ticket to the application server to demonstrate the authenticity of their identity. Each ticket has an expiry and can also be renewed. The kerberos server or KDC has no control over the issued tickets and if a user with a valid ticket can use the service until the ticket expires.
Key Distribution Center (KDC) / Kerberos Server
The kerberos server or KDC is logically incorporated further into multiple components.
- Database: Contains the user's service entries like user's principal, maximum validity, maximum renewal time, password expiration, etc.
- Authentication server: Replies to the authentication requests sent by the clients and sends back TGT which can be used by the user without re-entering the password.
- Ticket Granting Server (TGS): Distributes service tickets based on TGT and validates the use of ticket for a specific purpose.
Keytab
The keytab file contains pairs of kerberos principals and an encrypted copy of that principal's key. A keytab file for a hadoop daemon is unique to each host since the principal names include hostname. This file is used to authenticate a principal on a host to kerberos without human interaction or storing a password in a plain text file. The keytab file stores long-term keys for one or more principals.
Delegation Tokens
Users in hadoop cluster authenticate themselves to the namenode using their kerberos credentials. Once the user has logged off, user credentials are passed to the namenode using delegation tokens that can be used for authentication in the future. Delegation tokens are a secret key shared with the namenode, that can be used to impersonate a user to get a job executed. Delegation tokens can be renewed. By default, the delegation tokens are only valid for a day. Jobtracker as a renewer which is allowed to renew the delegation token once a day, until the job completes, or for a maximum period of 7 days. When the job is complete, the jobtracker requests the namenode to cancel the delegation token. Delegation tokens are generally used to avoid overwhelming the KDC with authentication requests for each job.
Token format
The namenode uses a random master key to generate delegation tokens. All active tokens are stored in memory with their expiry date. Delegation tokens can either expire when the current time exceeds the expiry date, or they can be cancelled by the owner of the token. Expired or cancelled tokens are then deleted from memory.
Kerberos Working
Generally, a user supplies password to a given network server and access the network services. The transmission of authentication information for most services is however unencrypted, and hence insecure. A simple password based authentication cannot be assumed to be secure. A simple packet analyzer or packet sniffer can be used to intercept usernames and passwords compromising user accounts and cybersecurity.
Kerberos eliminates the transmission of unencrypted passwords by authenticating each user to each network service separately. Kerberos does this by using KDC to authenticate users to a suite of network services. The machines that are managed by a particular KDC constitute a realm.
- When a user logs into his workstation, the user authenticates to KDC by a unique identity called principal. The principal is sent to KDC for a request of TGT (Ticket-Getting Ticket). This TGT request can be sent manually by the user through kinit program after the user logs in or it can also be sent automatically by the login program.
- KDC then checks for the principal in it's database. If the principal is found, KDC creates a TGT, encrypts it using the user's key and sends the TGT ticket back to that user's session.
- The login or kinit program decrypts the TGT using the user's key (computed from user's password). User's key is used only on client machine. The tickets sent by KDC are stored locally in a file credentials cache, which can be checked by kerberos aware services. Thus, this is how kerberos aware services look for the ticket on user's machine rather than requiring the user to authenticate using password.
- After TGT is issued, the user does not have to re-enter the password until the TGT expires or until the user logs out.
Authentication Process in Cloudera
Hadoop authenticates using below two ways:
- Simple: By default, Cloudera uses the simple authentication method where the client must specify a username and password of their respective Linux user account for any activity like HDFS query or MapReduce job submission.
- Kerberos: Here the HTTP client uses Simple and Protected GSSAPI Negotiation Mechanism (SPNEGO) for authentication purpose.
Using kerberos, if the namenode finds that the token already exists in memory, and that the current time is less than the expiry date of the token, then the token is considered valid. If valid, the client and the namenode will then authenticate each other by using the TokenAuthenticator that they posses as the secret key, and MD5 as the protocol. Since the client and namenode do not actually exchange TokenAuthenticators during the process, even if authentication fails, the tokens are not compromised.
Token Renewal Process
TGT renewal process is very important feature, due to which the long running jobs might actually take advantage of renewing the ticket so that they can continue running. Delegation tokens must be renewed periodically by the designated renewer.
For example, if jobtracker is designated renewer, the jobtracker will first authenticate itself to namenode. It will then send the token to be authenticated to the namenode. The namenode verifies the following information before renewing the token:
- The jobtracker requesting renewal is the same as the one identified in the token by renewerID.
- The TokenAuthenticator generated by the namenode using the TokenID and the masterKey matches the one previously stored by the namenode.
- The current time must be less than the time specified by maxDate.
Requirements
- All cluster hosts should have network access to KDC.
- Kerberos client utilities should be installed on every cluster host.
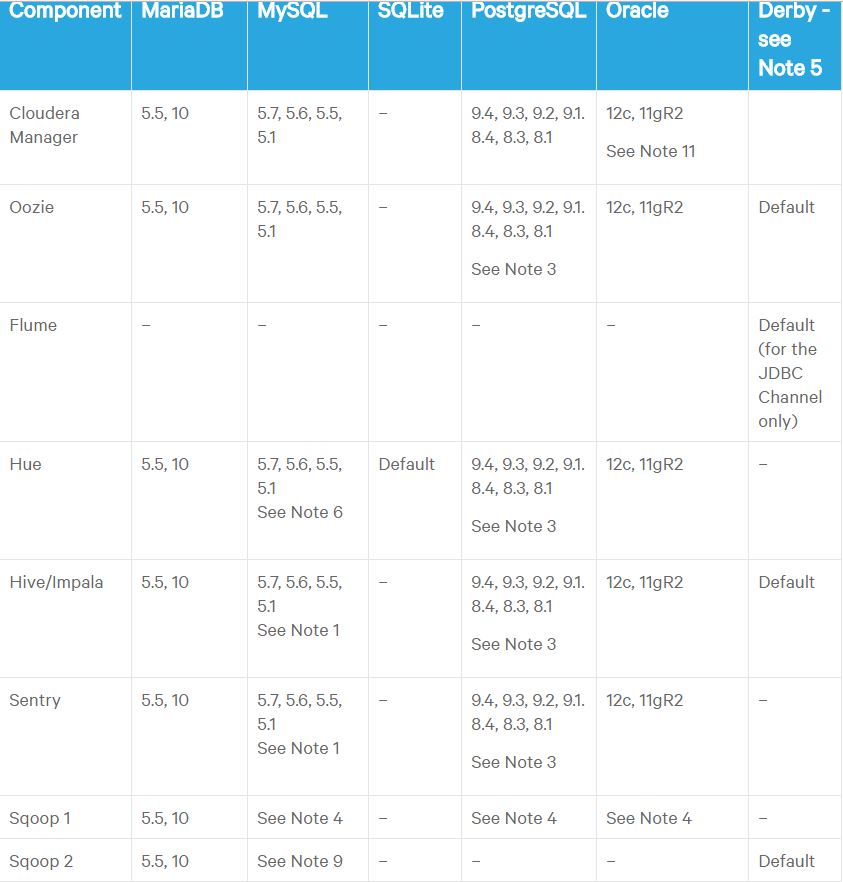
- Java Cryptography Extensions should be setup on all Cloudera Manager hosts in the cluster.
- All hosts are required to be configured in NTP for time synchronization.
KDC Server Installation
A KDC server can be a completely separate machine or can be a machine where Cloudera Manager is already running. The below mentioned procedure installs kerberos on a working cluster.
JCE Installation
Location:
First thing we need to do is install Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files. Download the Java 8 JCE files from
here. In case you are not sure of your java version, use the below command to find out your java version
# java -version
Next find the default location of local policy file.
# locate local_policy.jar
Unzip the downloaded policy file
# unzip jce_policy-8.zip
Copy the policy files to the default location.
# cd UnlimitedJCEPolicyJDK8
# cp local_policy.jar /opt/jdk1.8.0_121/jre/lib/security
# cp US_export_policy.jar /opt/jdk1.8.0_121/jre/lib/security
Package Installation
Different packages are required for both the server and client nodes.
Location: Server (nn.cdh.demo)
# yum -y install krb5-server krb5-libs krb5-auth-dialog krb5-workstation
Location: Client (nn.cdh.demo/dn1.cdh.demo/dn2.cdh.demo)
# yum -y install krb5-workstation krb5-libs krb5-auth-dialog
Server Configuration
Location: Server (nn.cdh.demo)
The kdc.conf file can be used to control the listening ports of the KDC and kadmind, as well as realm-specific defaults, the database type and location, and logging.
Configure the server by changing the realm name and adding some kerberos related parameters.
Realm Name: CDH.DEMO
Parameters: max_life = 1d
max_renewable_life = 7d
Note: All realm names are in uppercase whereas DNS hostnames and domain names are lowercase.
# vi /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
CDH.DEMO = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
max_life = 1d
max_renewable_life = 7d
}
Client Configuration
If you are not using DNS TXT records, you must specify the default_realm in [libdefaults] section. If you are not using DNS SRV records, you must include the kdc tag for each realm in the [realms] section. To communicate witht the kadmin server in each realm, the admin_server tag must be set in the [realms] section.
Set the realm name and domain-to-realm mapping in the below mentioned file.
Location: Clients (nn.cdh.demo/dn1.cdh.demo/dn2.cdh.demo)
# vi /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = CDH.DEMO
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[realms]
CDH.DEMO = {
kdc = nn.cdh.demo
admin_server = nn.cdh.demo
udp_preference_limit = 1
default_tgs_enctypes = des-hmac-sha1
}
[domain_realm]
.cdh.demo = CDH.DEMO
cdh.demo = CDH.DEMO
Initialize Kerberos Database
Create the database which stores the keys for the kerberos realm. The -s option creates a stash file to store master password. Without this file KDC will prompt the user for the master password everytime it starts after a reboot.
Location: Server (nn.cdh.demo)
# /usr/bin/kdb5_util create -s
Loading random data
Initializing database '/var/kerberos/krb5kdc/principal' for realm 'CDH.DEMO',
master key name 'K/M@CDH.DEMO'
You will be prompted for the database Master Password.
It is important that you NOT FORGET this password.
Enter KDC database master key:
Re-enter KDC database master key to verify:
The above command will create following files in "/var/kerberos/krb5kdc" path.
- two kerberos database files, principal, and principal.ok
- the kerberos administrative database file, principal.kadm5
- the administrative database lock file, principal.kadm5.lock
Adding Administrator for Kerberos Database
First create the principal "admin" which has administrator privileges using kadmin utility. This principal has to match the expression that you have specified in /var/kerberos/krb5kdc/kadm5.acl file. Also create "cloudera-scm" principal that will be used by Cloudera Manager to manage hadoop principals. The kadmin command is specifically used on the same host as KDC and does not use kerberos for authentication. We can create this principal with kadmin.local.
Location: Server (nn.cdh.demo)
# kadmin.local -q "addprinc admin/admin@CDH.DEMO"
# kadmin.local -q "addprinc cloudera-scm/admin@CDH.DEMO"
Note: To enable only "kadmin" command to add principals, we need to add principal root/admin@CDH.DEMO. Whereas "kadmin.local" will work normally.
Specifying Principals with Administrative Access
We need to create ACL file and put kerberos principal of atleast one of the administrators into it. This file is used by kadmin daemon to control which principal may view and make modifications to the kerberos database files.
Adding to Access Control Lists gives privilege to add principals for admin and cloudera-scm principal.
Location: Server (nn.cdh.demo)
# vi /var/kerberos/krb5kdc/kadm5.acl
*/admin@CDH.DEMO *
admin/admin@CDH.DEMO *
cloudera-scm/admin@CDH.DEMO *
Start Kerberos Daemons
Start kerberos KDC and administrative daemons
# service krb5kdc start
# chkconfig krb5kdc on
# service kadmin start
# chkconfig kadmin on
Verifying & Testing Kerberos
If a user is unable to access the cluster using "hadoop fs -ls /" command, and produces the below error, actually means that the Kerberos is functioning properly.
A user must be a kerberos user to perform hadoop tasks like listing files or submitting jobs. A normal user can no longer execute hadoop commands and perform hadoop tasks without seeing the above error, until his/her user is authenticated using kerberos.
Create UNIX user
# useradd user1
# passwd user1
Create a user principal in kerberos
# kadmin.local
kadmin.local: addprinc user1
Request a ticket
# kinit user1
Or, login as user1 and request for a ticket by issuing kinit command without specifying username as "user1".
# su - user1
$ kinit
Diplay the ticket and encryption type information
# klist -e
The above screenshot shows that user1 has received TGT from KDC and the ticket is valid for only 1 day.
Managing Principals
First run kinit to obtain a ticket and let it store in credential cache file. Then use klist command to view the list of credentials in the cache. To destroy the cache and it's credentials use kdestroy.
Specifying queries with/without entering the kadmin console.
List principals
# kadmin.local admin/admin -q "list_principals"
kadmin.local: list_principals
Add new principal
# kadmin.local -q "addprinc user1"
kadmin.local: addprinc user1
Delete principal
# kadmin.local -q "delprinc user1"
kadmin.local: delprinc user1
Delete KDC database
# kdb5_util -f -r CDH.DEMO destroy
Backup KDC database
# kdb5_util dump kdcfile
Restore KDC database
# kdb5_util load kdcfile
Display ticket and encryption type
# klist -e
Exit kadmin utility
kadmin.local: quit
Kerberos Security Wizard
Once all hosts are configured with kerberos, configure kerberos for Cloudera Manager. The following steps need to be performed from Cloudera Manager Admin Console. The Cloudera Manager Admin Console can be accessed from a browser by typing the following URL, http://<cloudera-manager-server-IP>:7180. In our case it can be accessed by typing the URL - http://192.168.56.101:7180.
Click on "Administration" tab and then click on "Security" from the drop-down menu.
Configure kerberos by clicking on "Enable Kerberos".
Make sure the KDC is setup, openLDAP client libraries shoud be installed and cloudera-scm principal is created as specified in below screenshot.
Once all dependencies have been resolved, select all and click on "Continue".
Specify the necessary KDC server details required to configure kerberos like KDC server host, realm name and various encryption types, etc.
Configure krb5 as shown in below screenshot.
Specify the account to manager other users' principals.
Specify the principals that will be used by services like HDFS, yarn and zookeeper.
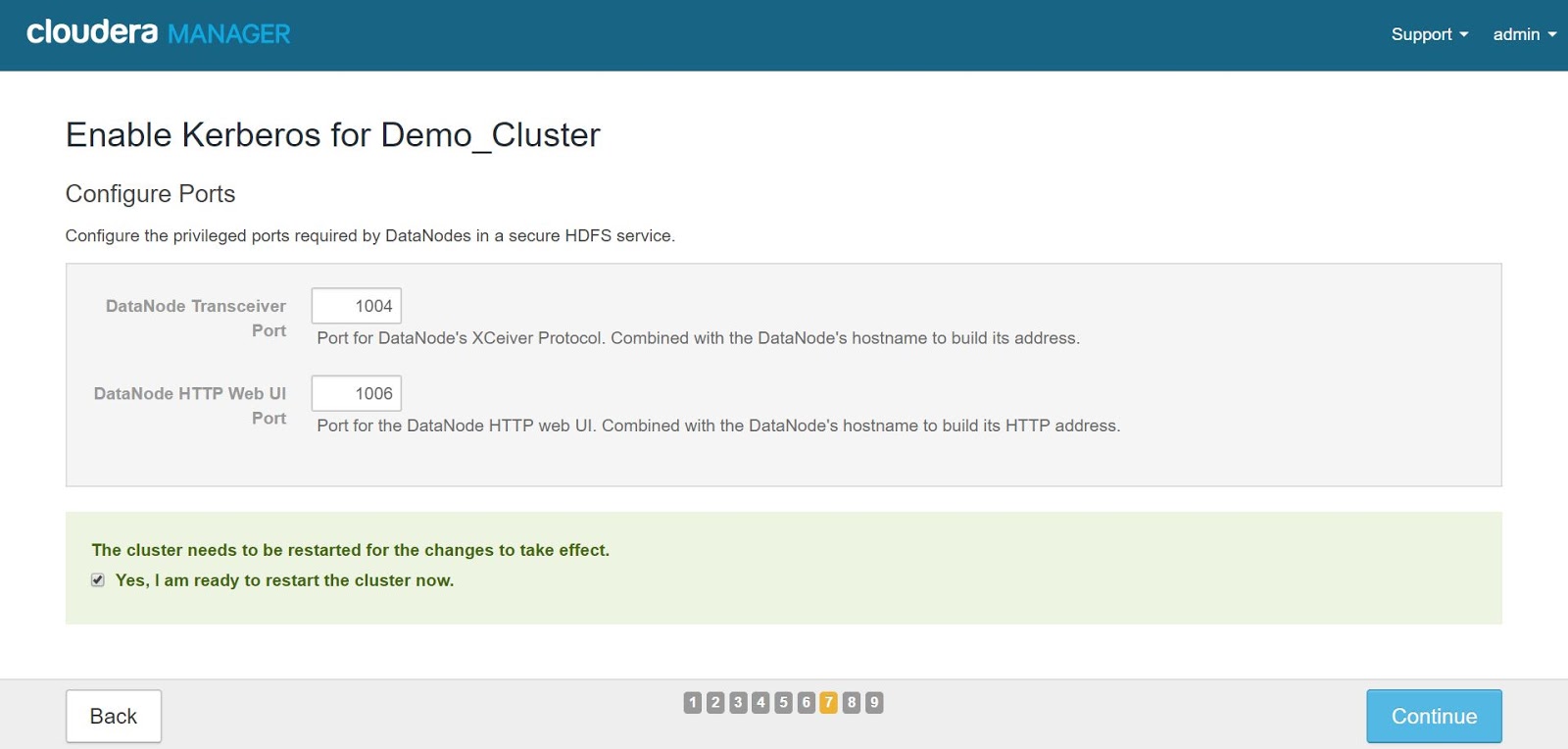
Configure the privileged ports required by datanodes in a secure HDFS service.
Finally the cluster is kerberized.
References:
- https://blog.godatadriven.com/kerberos-cloudera-setup.html
- http://blog.puneethabm.in/configure-hadoop-security-with-cloudera-manager-using-kerberos/
Related Posts:
Cloudera Multi-Node Cluster Installation
TAGS:
cdh 5.9.1,
cm,
cdh 5.9.1 security,
cdh 5.9.1 security implementation,
cloudera hadoop kerberos,
kerberos,
cloudera hadoop cdh 5.9.1 security,
hadoop multinode cluster kerberos,
install and configure kerberos on cloudera hadoop,
install kerberos cdh 5.9.1,
install kerberos on cloudera hadoop multinode cluster,
install kerberos on cloudera hadoop,
latest cloudera hadoop,
kerberos on multinode hadoop cluster installation